
![]() Besides Btrfs, native Linux-based storage solutions have lagged behind the robustness and features of ZFS and the BSDs. Recently Red Hat acquired Permabit which provides an Open Source device-mapper Linux kernel driver and layer that sits between block devices and filesystems providing deduplication, compression and thin provisioning. Here’s my first experiences setting it up and initial returns using it.
Besides Btrfs, native Linux-based storage solutions have lagged behind the robustness and features of ZFS and the BSDs. Recently Red Hat acquired Permabit which provides an Open Source device-mapper Linux kernel driver and layer that sits between block devices and filesystems providing deduplication, compression and thin provisioning. Here’s my first experiences setting it up and initial returns using it.
What’s this VDO Thing?
VDO stands for Virtual Data Optimizer. It’s a Linux device-mapper driver that provides innate storage capabilities to underlying block devices like deduplication, compression and thin-provisioning. There’s only a few elements to VDO: kernel drivers and some user-space tools.
- kvdo kernel module: this controls block level activities and compression
- uds kernel module: this manages the deduplication index
- vdo, vdostats tools: these tools help you manage VDO volumes or display information and statistics about usage and block devices, metadata.
Architecture
VDO sits at the device-mapper layer, above block devices but below the filesystem. For the graphically inclined here’s a diagram.
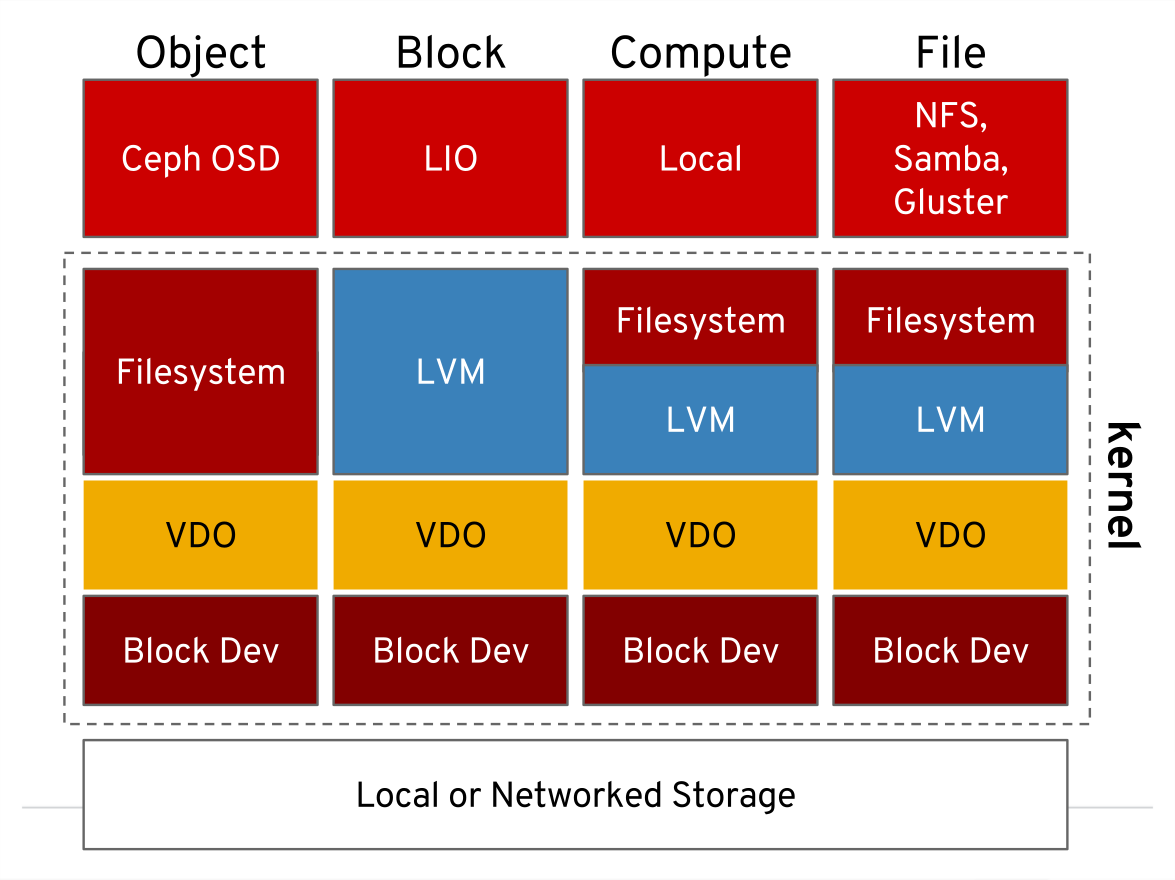
How Does it Work?
VDO data reduction technology works at the OS layer so it can benefit all layers above it. It works by first eliminating 4KB zero byte blocks and duplicate blocks and then adds compression to the remaining blocks. There is obviously a performance and memory cost to these processes however. Here’s a diagram that better explains it:

Memory Considerations
Like ZFS, VDO relies on a certain amount of physical memory for the amount of block storage you want to manage underneath it. In general a good rule of thumb (according to the docs) is:
- 500MB memory plus 268MB per 1TB of physical storage
- e.g. our 33TB RAID6 volume below would require at minimum 8.63GB of memory.
These measurements are much more conservative than ZFS in general, though ZFS does a little more like COW snapshots.
Installing VDO
Let’s jump right into installation. VDO Permabit kernel modules, service and user-space tools are available inside the base repositories for CentOS7.4 or RHEL7.4 or higher.
yum install vdo kmod-kvdo
Now you’ll want to start the VDO service
systemctl start vdo systemctl enable vdo
Creating VDO Volumes
Now you’re ready to create some volumes, in our case we’re going to create a thin-provisioned volume on top of an nVME disk.
vdo create --name=vdo_NVME --device=/dev/nvme0n1p1 \ --vdoLogicalSize=5T --writePolicy=async
Above, this will create a VDO volume named vdo_NVME on our chosen device. Our actual physical disk size is 845Gb so we’re going to thin-provision roughly 6x to 5T.
Creating VDO vdo_NVME Starting VDO vdo_NVME Starting compression on VDO vdo_NVME VDO instance 0 volume is ready at /dev/mapper/vdo_NVME
At this point just create a filesystem, mount it somewhere and start using it.
mkfs.xfs -K /dev/mapper/vdo_NVME
Note about Write Modes
I chose the async write policy here for performance reasons, but you should read the following descriptions to pick what’s right for you.
sync – writes to the VDO device are acknowledged when the storage has written the data permanently.
async – writes are acknowledged before being written to storage. In this mode, VDO is also obeying flush requests from the layers above. Even in async mode it can safely deal with your data, this is equivalent to other devices with volatile write back caches. This is the right mode if your storage itself is reporting writes as ‘done’ when they are not guaranteed to be written.
auto – this is now the default, which selects async or sync write policy based on the capabilities of the underlying storage.
You can read more in the documentation here.
Creating Large VDO Volumes
Creating large volumes may need adjustment of the Slab Size variable. A Slab is how VDO physically divides contiguous regions of block storage (think of it like LVM extents). The default slab size is 2G but they can be any power of 2, multiple of 128 MB up to 32 GB.
When using 32 GB slabs, the maximum allowed physical storage is 256 TB but in our example we’re going to use an existing 33TB RAID6 MDADM volume.
Creating Volumes with Maximum Slab Size
Our setup here will use an existing MDADM Linux software raid device (11 x 4TB SATA in RAID6) /dev/md3. We’re also going to thin-provision our 33TB physical mdadm device by 10x into 300TB
Note that this is an existing volume that was previous mounted and used and had an existin filesystem. We first need to unmount the MDADM volume
umount /dev/md3
Now we can proceed with re-purposing this as a VDO volume first, but we’ll need –force since we’re leaving the mdadm device intact (though we’ll reformat it later).
vdo create --name=vdo_public --device=/dev/md3 \ --vdoLogicalSize=300T --vdoSlabSize=32G --writePolicy=async --force
Creating VDO vdo_public Starting VDO vdo_public Starting compression on VDO vdo_public VDO instance 1 volume is ready at /dev/mapper/vdo_public
Next, we’re going to need to reformat the filesystem because VDO sits below the filesystem layer but above the physical block device layer. Note that this wipes all data on the previously used raw /dev/md3 device that was formatted as XFS.
mkfs.xfs -K /dev/mapper/vdo_public
Usage and Savings
You can use the vdostats user-space tool to view details on your VDO volumes, including savings and a slew of other metadata, stats and other information.
After a week of copying VM backups (qcow2 images, sparse files) to our vdo_public volume we see a savings rate of around 41%.
vdostats --human-readable /dev/mapper/vdo_public
Device Size Used Available Use% Space saving% /dev/mapper/vdo_public 32.7T 2.4T 30.4T 7% 41%
Let’s compare that with a regular df (disk free) output.
df -h /dev/mapper/vdo_public
Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo_public 300T 3.1T 297T 2% /mnt/storage_vdo_pub
Also note df reports 300TB, 10x our physical space due to thin provisioning. As I start to store different types of data I will update this blog post to reflect.
VDO Data Types and Savings
While I’ve only been using VDO-backed storage for mostly scratch space and VM image backups there’s some interesting data available about the types of savings yield you can expect depending on your data.
The following were taken from a presentation on VDO at the Gluster Summit in 2017.

Here is a good breakdown of storage savings for container images for example:

Performance Observations
I’ve only been running VDO on my two volumes for a few weeks now but in general these are my observations on a SuperMicro 6029P-TRT.
This is with (2) VDO volumes
- 33TB (MDADM, RAID6, 11 x 4TB SATA, thin provisioned to 300TB)
- 845Gb nVME (thin provisioned to 5TB)
- kvdo uses around 8-10% of the CPU at all times
- 12-14GB memory usage from all vdo processes
- mdadm uses 10-12% CPU (specific to my setup)
- nfsd uses anywhere from 15% to 60% CPU (specific to my setup, heavy NFS)
- Fairly high I/O wait, load average ~16 to ~40 (with 56 vcpu)
This is out of the box with no real tuning besides the throughput-performance tuned profile
%CPU COMMAND 12.9 md3_raid6 8.9 kvdo1:physQ0 7.3 kvdo1:hashQ0 7.0 kvdo1:cpuQ0 7.0 kvdo1:cpuQ1 6.6 kvdo1:logQ0 5.0 kvdo1:journalQ 4.3 kvdo1:packerQ 3.3 kvdo1:ackQ 3.0 kvdo1:dedupeQ 2.0 kvdo1:bioQ0 2.0 kvdo1:bioQ1 2.0 kvdo1:bioQ2 2.0 kvdo1:bioQ3
First Thoughts
My first thoughts were “Wow, this is great. I can also just yum install it without a bunch of hoops.” I was pretty excited about the initial returns as well.
I also expected some rather demanding system utilization as I was used to deploying and managing ZFS-based storage like FreeNAS or just regular ZFS on top of FreeBSD.
What’s lacking is here is COW snapshot functionality but I’m sure that’s on the roadmap.
I’ll be keeping this updated as I experiment more, and also look forward to reporting some best practices on tuning and internals once I learn what they are. I also want to test out the replication functionality once I get another system stood up.
Here’s the link to the official vdo storage documentation which explains a lot more than this post does currently.








Nice write-up. Thank you!
LikeLike
Hi there, I have created 2 vdo devices (/dev/mapper/vdo1, /dev/mapper/vdo2) on 2 physical devices (/dev/sdc, /dev/sdd).
created Logical Volume(vdo_lvm) on 2 vdo devices.
Now my system crashed and reinstalled OS.
Can anyone know how to recover data from logical volume (vdo_lvm) ?
in my case i’m unable to find vdo devices, vgexport, no data.
LikeLike
Why not use LVM snapshots?
LikeLike
Hey Brian, LVM solves a different problem. VDO below the filesystem and right above block devices and provides active deduplication and compression, thin-provisioning – things sitting on top of it are completely unaware. VDO does not provide snapshot functionality by itself, though you could certainly leverage LVM snapshots sitting on top of VDO.
LikeLike
Hey Will. Indeed. I know very well about LVM snapshots. I use them all of the time.
What I am wondering is why you think (CoW) snapshots in VDO would be better than LVM’s own CoW snapshots. I’m not sure I see the point in VDO implementing snapshots when LVM does them.
LikeLike
Hey Brian, at the time of writing this guide VDO did not support CoW snapshots at all. If it did, for me personally in most cases I would always be using VDO but I might not be using LVM so I might prefer to snapshot at the vdo-level as a common denominator, lower on the device/fs/dm layer and present in everything above it. This would assume all common feature parity and efficiencies found in existing CoW implementations. Outside of object storage with VDO LVM snapshots would be awesome, it’s a great compliment.
LikeLike
Hello friend, nice article, do you know how prone to corruption is this vdo thing in case of power cut?
LikeLike
We’ve lost power a few times and not had any issues, I think it’s more important making sure you are using a journaling filesystem on top of the block devices that are managed by VDO – we’re using XFS here but EXT4 would be a good choice too.
LikeLike